Getting the Most from GitHub Copilot and AI Models - Boost Productivity While Managing Costs
🤖 The Day My AI Assistant Became Smarter Than Me (And Cheaper Too)
“Hey Copilot, write me a function to…”
Does this sound familiar? You reach for the most powerful AI model every time—whether you’re naming a variable, writing quick documentation, or adding a simple code comment. Claude 4 for everything. GPT-4 for the basics. Premium models, always on.
It’s like driving a Ferrari just to check your mailbox.
What changed for me? I stopped treating AI like a one-size-fits-all hammer and started seeing it as a toolbox—each model with its own strengths.
That was my turning point. Once I matched the right model to each task, my productivity soared and my costs dropped dramatically.
In this post, I’ll share the practical framework I use to choose the best AI model for every job—so you can avoid overkill and get the most value from your tools.
Ready to turn your AI chaos into a cost-effective, productivity-boosting machine?
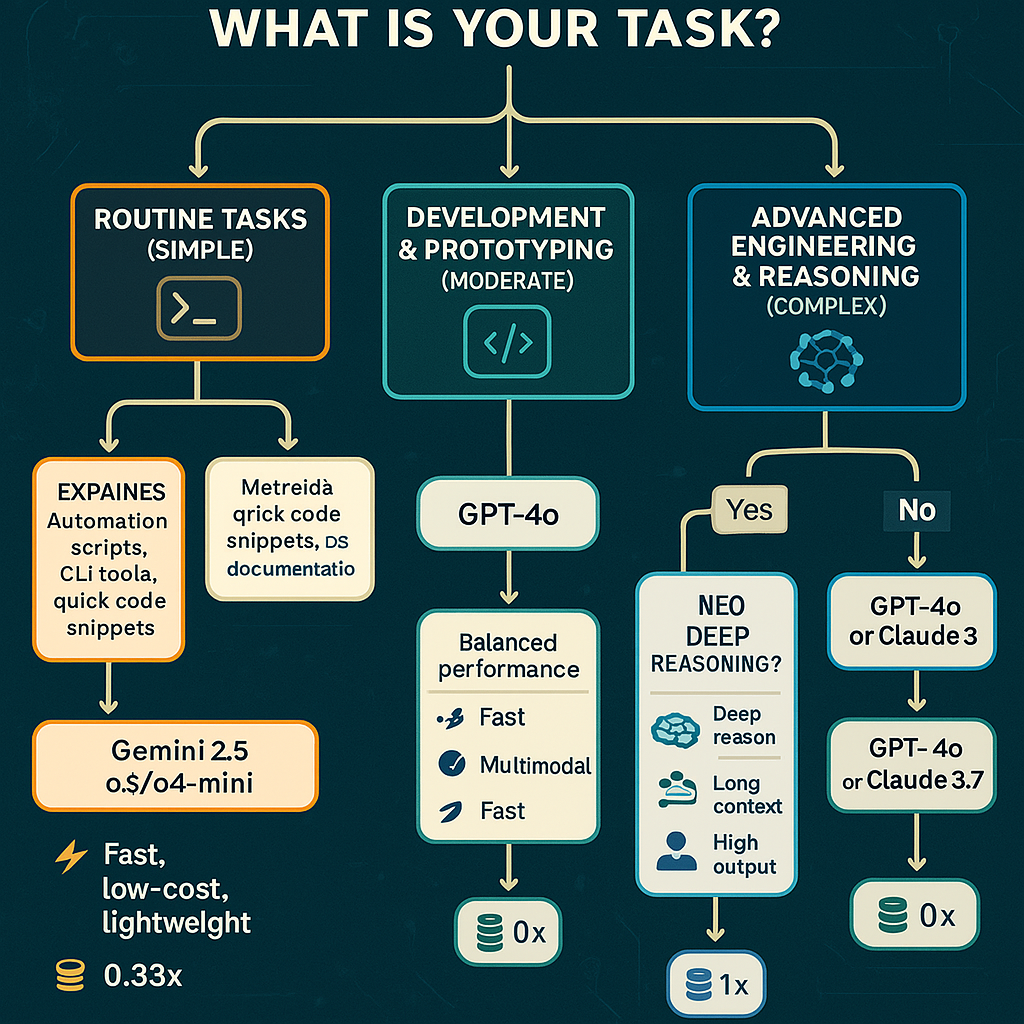
At first, I tried to optimize by combining multiple requests into single prompts. While that helped a bit, it wasn’t enough. I realized I needed a more strategic approach.
Through experimentation, trial and error, and a lot of learning, I eventually discovered how to balance performance and cost. I learned when to use lightweight models for quick tasks, and when to bring in more powerful models like Claude 4 or GPT-4 for deep reasoning and complex code analysis.
Today, Copilot is more than just a tool—it’s my coding partner. I’ve developed a practical framework for using it efficiently, and I continue to refine that approach as the tools evolve.
This journey has taught me that the key to getting the most out of AI isn’t just access—it’s understanding how and when to use it wisely.
As a tech enthusiast, I’ve always been fascinated by how AI can supercharge developer productivity. With access to GitHub Copilot Pro and a suite of powerful models like GPT-4.1, Claude 4, Gemini 2.5, and others, I found myself asking a critical question:
“How do I get the best results from these models without burning through tokens and cost?”
So began my journey into understanding when to use which model, and how to combine them with the right agents to strike the perfect balance between performance and cost.
🧠 The Models at My Fingertips
I had access to a powerful lineup:
| Model | Key Features | Best For |
|---|---|---|
| GPT-4.1 | Versatile, fast, cost-effective, large context window, prompt caching, batch processing | Quick code generation, creative writing, multi-turn conversations |
| Claude Sonnet 4 | Deep reasoning, long-context (200K tokens), large output (64K tokens), strong summarization | Deep code analysis, long document summarization, complex logic tracing |
| Gemini 2.5 Pro | Lightweight, blazing fast, efficient for short tasks | Automation scripts, rapid prototyping, low-latency tasks |
| Mini/Nano models | Minimal resource usage, ultra-fast, cost-saving | Automation, scripting, repetitive or low-risk tasks |
Each model had its strengths, but using them blindly would be like using a sledgehammer to crack a nut—or worse, using a nutcracker to break concrete.
🧩 The Realization: Context Matters
One of the first things I learned was the importance of context windows:
| Model | Context Window | Max Output Tokens | Best Use Cases |
|---|---|---|---|
| Claude 4 | 200K tokens | 64K tokens | Deep code analysis, long document summarization |
| GPT-4.1 | 1 million tokens | Not specified | Multi-turn conversations, large-scale planning |
| Gemini 2.5 Pro | 128K tokens (varies by tier) | Not specified | Rapid prototyping, automation, low-latency tasks |
| Mini/Nano | 4K–16K tokens (model dependent) | Not specified | Automation, scripting, repetitive/low-risk tasks |
Choosing the right model means matching your task to the context window and output needs—don’t overpay for power you don’t need!
But here’s the catch: not every task needs that much power.
🔍 The Experiments
I began testing these models on real-world development tasks to see which excelled where:
| Task/Use Case | Best Model | Why/Notes |
|---|---|---|
| Writing functions, classes, tests | GPT-4.1 | Fast, accurate, great for generating and refining code snippets |
| Refactoring legacy code (multi-file) | Claude 4 | Excels at understanding and restructuring complex, cross-file codebases |
| Debugging common bugs/stack traces | GPT-4.1 | Quickly identifies and suggests fixes for typical errors |
| Tracing deep logic errors | Claude 4 | Handles complex reasoning and uncovers issues in intricate business logic |
| Summarizing long meeting notes | Claude 4 | Processes large documents and produces concise, structured summaries |
| Generating quick documentation | GPT-4.1 | Efficient for short drafts, API docs, and email responses |
| Writing automation scripts | Mini/Nano | Lightweight, cost-effective for repetitive scripting tasks |
| Brainstorming/creative writing | GPT-4.1 | Flexible and fluent for ideation, blog posts, or creative content |
| Reviewing pull requests | Claude 4 | Deep context window helps analyze large diffs and provide thorough feedback |
| Generating test data/mocks | Mini/Nano | Fast and cheap for creating sample data or mock objects |
| Codebase search & summarization | Claude 4 | Handles large codebases, summarizes architecture or dependencies |
| Rapid prototyping | Gemini 2.5 | Blazing fast for quick iterations and proof-of-concept tasks |
💰 Cost vs Value
I also learned to respect the token meter:
| Model | Cost Level | Key Savings Features | Best For |
|---|---|---|---|
| Claude 4 | $$$ (Premium) | Deep reasoning, long context, large output | Complex analysis, summarization |
| GPT-4.1 | $$ (Moderate) | Prompt caching, batch processing discounts | Code generation, multi-turn conversations |
| Gemini 2.5 | $ (Affordable) | Fast, efficient for short tasks | Rapid prototyping, automation |
| Mini/Nano | $ (Lowest) | Minimal resource usage, ultra-fast | Repetitive, low-risk scripting tasks |
By matching the right model to the right task, I reduced my token usage by over 40% without sacrificing quality.
🧭 Final Thoughts
This journey taught me that AI is not just about power—it’s about precision. Knowing when to use Claude 4’s deep reasoning or GPT-4.1’s versatility is what separates a good developer from a great one.
If you’re navigating the same landscape, I hope this story helps you make smarter, more cost-effective decisions.
Use the right model, at the right time, for the right task.
Related Posts
- Enable CI against all Branches
- Branch Protection as Code Enforce GitHub Security at Scale
- DevOps Attitude
- Manage Azure DevOps Pipelines Variables
- VSTS Build and Release Agents
About Ajeet Chouksey

Ajeet Chouksey
- Getting the Most from GitHub Copilot and AI Models - Boost Productivity While Managing Costs
- The Evolving Role of the Product Owner in the Age of AI
- Supercharging Code Reviews with AI for Strategic Impact
- Branch Protection as Code Enforce GitHub Security at Scale
- Governance Layer Best Practices in GitHub
- Deploy and Configure SonarQube
- Azure Bastion
- DevOps Attitude